学习扑克GTO:策略、工具与常见误解解析
GTO 代表 “Game Theory Optimal(博弈论最优)”。近年来,GTO 的概念在扑克界变得非常流行。GTO 扑克策略的目标是以一种方式进行游戏,使对手无法利用你策略中的任何弱点。
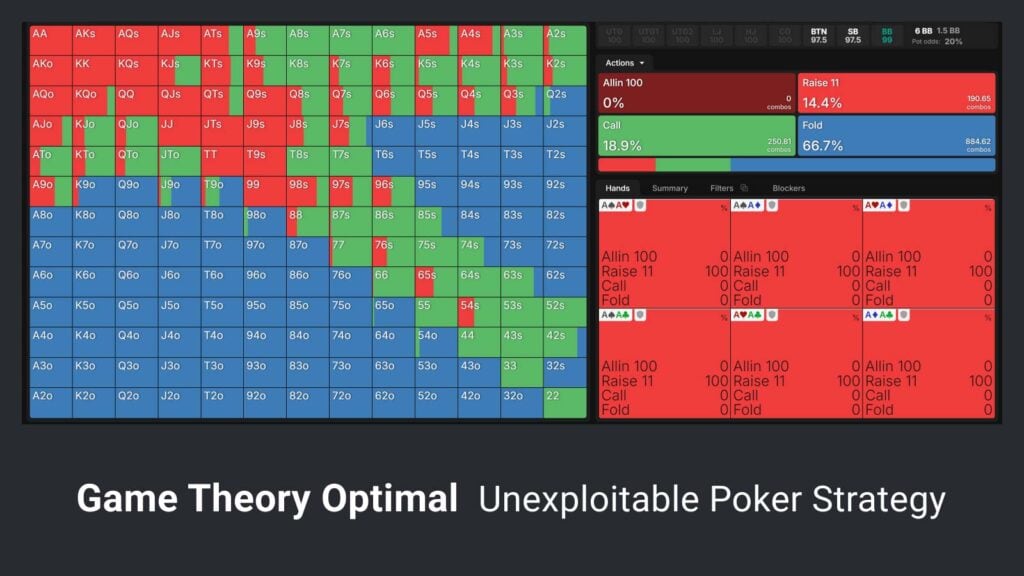
使用 GTO 策略的玩家能够以特定频率混合多种行动,从而确保无论对手怎么做,他们都能始终保持盈利,或者至少不亏损。
GTO 扑克基础
要理解 GTO 扑克,你需要先理解 ⚖️ 纳什均衡(Nash Equilibrium)。下面用一个简单的例子来说明:
- 玩家 A 在河牌首先下注一个满池,并以 80% 的诈唬和 20% 的价值牌进行混合。
- 为了应对这种策略,玩家 B 对所有河牌下注都选择跟注。
- 玩家 A 调整策略,现在以 75% 的价值牌和 25% 的诈唬下注。
- 于是玩家 B 开始对多达 70% 的河牌下注选择弃牌。
- 玩家 A 再次调整,现在是 66% 的价值牌和 33% 的诈唬。
- 玩家 B 则对 50% 的河牌下注选择弃牌。
此时双方的策略已经达到纳什均衡。也就是说,任何一方都无法通过改变自己的策略来提高期望值(EV)。当玩家 A 诈唬时,玩家 B 跟注会获得更高收益;而当玩家 B 弃牌时,玩家 A 的诈唬会更盈利。

当你运行GTO 求解器(solver)软件时,它会分析在每一种策略选择下可能发生的所有情况,以找到纳什均衡。
最小防守频率(MDF)
每个职业玩家都需要了解最小防守频率(Minimum Defense Frequency)。它表示为了避免被对手利用,你需要继续游戏的手牌比例。也就是说,通过保持这个频率,可以防止对手从你的策略中获得额外优势。
直观来说,最小防守频率(MDF)取决于对手的下注大小。面对较大的下注时,大多数玩家都知道应该用更少的手牌继续游戏;而面对较小的下注时,你可以用更多的手牌继续。
💡 计算 MDF 的公式为:MDF = 底池大小 / (底池大小 + 下注大小)
例如,对手下注 $50,而底池是 $100。MDF = 100 / (100 + 50) = 67%。这意味着你应该继续游戏的手牌占 67%。换句话说,在完美的 GTO 策略下,你应该有 33% 的时间弃牌,其余 67% 的时间继续(可以跟注或加注)。
在使用 GTO 扑克策略时,最好从整体手牌范围(range)的角度思考,以及它如何随着每一条街和你与对手的每一次行动而变化。
当你知道面对对手下注需要弃掉多少手牌后,就需要决定哪些手牌继续游戏。通常你会继续使用最强的手牌,同时加入一些边缘牌,这些牌在后续街道上有不错的改进潜力。
GTO 防守示例
让我们来看一个例子:在 Big Blind 对抗 Button 的持续下注时的 GTO 防守策略。翻牌为 A♠ 9♥ 8♥。
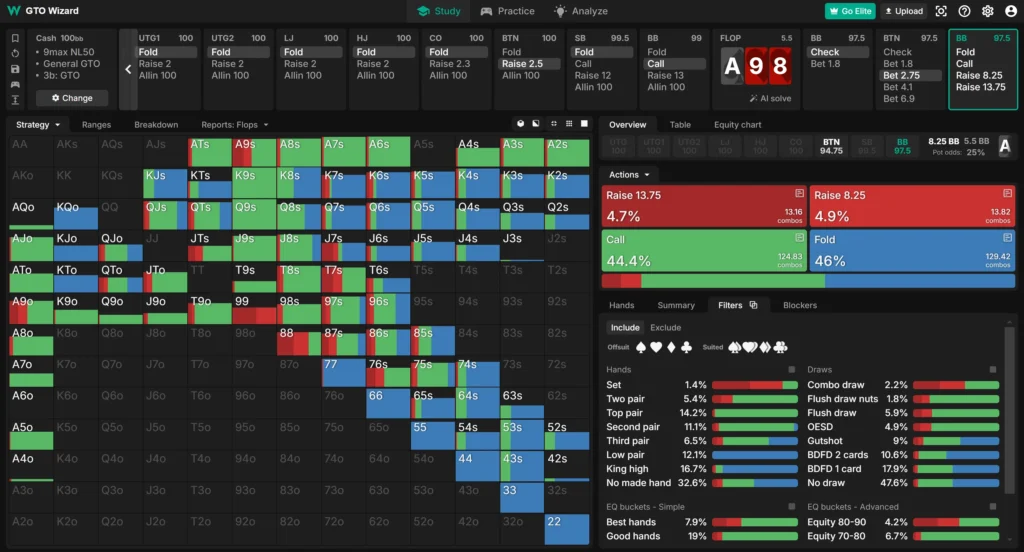
如图所示,我们应该有 9.6% 的时间加注,44.4% 的时间跟注,46% 的时间弃牌。
保持平衡的范围
GTO 扑克的核心思想是始终保持策略平衡。当你进行下注或加注时,需要弄清楚两件事:
- ❓ 价值下注与诈唬之间的最佳比例是多少?
- ❓ 在不同情况下,哪些类型的手牌最适合用来诈唬?
这些问题的答案取决于手牌中的多个因素:
- 底池大小和下注尺度
- 筹码与底池比例(SPR)
- 公共牌面结构
- 参与牌局的玩家数量
很多玩家在构建自己的范围时依赖直觉,但直觉并不一定是最优的。因此你的范围可能会失去平衡,对手也就更容易利用你。
因此,使用 solver 分析不同场景非常重要。它们可以帮助我们摆脱主观判断,找到最优策略。GTO 求解器会根据你设定的下注尺度和公共牌面,计算出最佳的价值下注数量和最佳的诈唬数量。
GTO 持续下注示例
下面来看一个平衡的持续下注范围示例。我们仍然使用前面的场景,不过这次从 Button 的角度来看。Button 对 Big Blind 的持续下注策略如下:
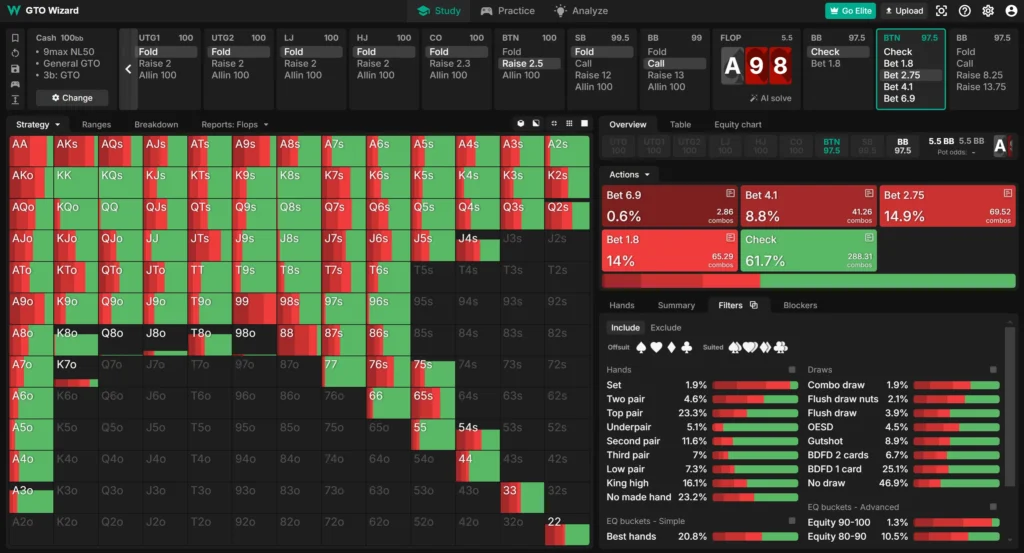
在这个场景中,我们的下注频率并不高。只有 38.3% 的时间下注,而 61.7% 的时间选择过牌。
GTO 扑克工具
认真对待扑克的玩家通常会使用 GTO 工具来学习扑克理论。这些软件通过复杂的数学模型计算在每个可能场景下的最优策略,并帮助你理解 GTO 概念。下面我们将介绍两款最好的 GTO 学习工具。
免费 GTO 翻前工具
你可以先从我们的免费翻前工具开始。使用 GTO 翻前范围 学习按位置和场景划分的基础 GTO 范围;再使用 GTO 翻前训练器 快速练习这些决策并跟踪你的准确率。若想更深入学习 GTO,可继续查看下方的进阶工具。
GTO Wizard
学习 GTO 扑克策略的最佳方式之一是使用 GTO Wizard。这是目前市场上最受欢迎的 GTO 软件之一,同时也是最现代、最便捷的工具。我们在上面的示例中使用的正是这款应用。
与传统 solver 不同,你不需要在电脑上安装软件或进行复杂计算。GTO Wizard 在浏览器中运行,界面直观,即使是初学者也能轻松使用。
GTO Wizard 主要功能
- 🎓 Study: 从 GTO 视角探索几乎任何牌局场景,拥有超过 1000 万个预先计算好的局面。只需通过简单的界面设置行动和公共牌,就能查看所有玩家的 GTO 范围。
- 🎮 Practice: 使用训练模式测试你的 GTO 理解。在与 GTO 对手对局时做出决策,系统会从 GTO 角度评估你的每一次行动。
- 💡 Analyze: 上传你的手牌记录,从 GTO 的角度分析你在牌局中的所有错误。
在我们的GTO Wizard 评测文章中了解更多信息。请注意,你还可以在首次订阅 GTO Wizard 时获得 10% 折扣和额外奖励。
PioSOLVER
PioSOLVER 是一款经典的 solver,需要安装在电脑上,并由你自己运行计算来分析任何配置好的场景。PioSOLVER 引擎可以快速计算翻牌后扑克游戏的所有可能结果,并支持自定义范围、筹码深度和下注尺度。
PioSOLVER 功能:
- 对翻牌、转牌和河牌进行快速且精确的计算;
- PioVIEWER 用于可视化查看求解结果;
- 构建、保存和加载策略树;
- 权益图表;
- 以及更多功能。
PioSOLVER 是一个强大的程序,可以在复杂的翻牌后场景中(例如转牌和河牌)准确计算纳什均衡。如果你是高级玩家,而 GTO Wizard 的预计算方案无法满足你的需求,可以考虑使用 PioSolver 在本地设备上进行自定义计算。
关于 GTO 扑克的常见误解
自从 GTO 在扑克界流行起来后,人们对它进行了大量讨论,但其中很多说法并不准确。下面我们将澄清一些常见的误解。
❌ 想赢扑克就必须打出完美 GTO
这是初学者最常见的误解。很多人认为只要学习 GTO 范围就能赚很多钱,但实际情况并非如此。
👉 GTO 策略只有在对手也使用 GTO 时才是理想策略。如果所有人都打 GTO,唯一能赚钱的只有收取抽水(rake)的扑克平台。
扑克中还有另一种基本思路——剥削(Exploit)。通过研究对手的习惯,你可以制定剥削策略,从他们的错误中获利。想了解更多关于玩家池分析的内容,可以阅读这篇关于扑克中的大数据分析(MDA)的文章。
想在高额级别取得成功,你需要将 GTO 和 MDA 方法结合起来使用。
❌ 同一种策略可以适用于多个场景
很多人认为某些 GTO 思路在任何情况下都适用。但实际上,solver 的策略会根据很多因素发生变化。在一个场景中的最佳打法,在另一个看似相似的场景中可能完全不同。
在学习 GTO 的过程中,你可能会发现一些模式。这对于在脑海中建立 GTO 的整体框架很重要。但请记住,GTO 策略非常复杂,你需要研究成千上万种情况,才能逐渐学会像 solver 一样思考。
❌ GTO 扑克只适用于高额级别
不仅是高额玩家,各个级别的玩家都可以使用 GTO 策略,或者至少应该理解其基础原理。无论打什么级别,当你面对不熟悉的对手时,都建议以 GTO 为基础进行游戏。
也有人认为在低级别对抗经验较少的玩家时不应该使用 GTO,因为最好的方式是利用他们的弱点来赚钱。这种说法有一定道理。但问题是:如果你不了解一个玩家的打法,又该如何利用他呢?
如果你把 GTO 作为默认策略,就可以在降低自身犯错概率的同时观察对手的行为。一旦发现对手的漏洞,你就可以调整策略来针对他们的弱点。
GTO 扑克 vs 剥削打法
正如我们前面提到的,GTO 扑克的核心目标是确保我们的策略不会被利用,并始终保持范围平衡。
剥削型扑克则是通过利用对手的错误来赚钱。为了利用这些错误,我们有时需要牺牲策略平衡。但问题在于:这样一来,我们自己的策略也可能被对手利用 🤷♂️

在采用剥削策略时,找到对手的漏洞非常重要。但也要小心,因为如果对手发现你的漏洞,他们也可能反过来利用你。
面对遵循 GTO 原则的强手时,我们通常也需要在大多数情况下使用接近 GTO 的策略。而面对较弱的对手时,切换到剥削型打法往往能带来更高收益——只要我们避免犯下代价巨大的错误。
💡 优秀的玩家会有效地结合 GTO 与剥削策略。面对未知或强大的对手时,以 GTO 为基础;一旦发现对手的具体漏洞,就逐渐偏离 GTO 范围来利用这些错误。但要记住,偏离 GTO 也会让你变得更容易被利用,因此需要谨慎使用。
级别越高,你越需要关注自己的范围,因为对手也会仔细观察你的错误。在低级别,你几乎可以完全专注于剥削打法。整体水平较低,几乎没有人真正遵循 GTO 频率。不过,即使在低级别,理解 GTO 概念也能让你获得优势,因为你能更清楚地看到对手在哪些地方偏离 GTO,从而更有效地利用他们的错误。
如何开始学习 GTO?
人类无法打出完美的 GTO 扑克。记住并在牌桌上执行 100% 最优的 GTO 策略几乎是不可能的,因为游戏太复杂、变量太多。
不过,你仍然应该把 GTO 学习纳入你的扑克训练计划中。通过不断学习,你会逐渐掌握 GTO 概念,并记住不同场景下的频率和模式。
首先从建立最佳的翻前范围开始,并考虑你所玩的游戏中的抽水结构。你可以在 GTO Wizard 中探索翻前场景,然后将其导入 Freebetrange,创建一个简化的策略,方便训练和记忆。
建立翻前策略后,你可以继续研究翻后场景,例如在 GTO Wizard 或 PioSolver 中学习。学习 GTO 并没有唯一正确的方法,关键是持续练习。我们建议从 GTO 角度分析最近一场牌局中的手牌,因为这些场景你已经经历过,更容易记住。
当你真正理解 GTO 的运作方式后,就可以在实战中应用这些策略。你需要根据基本的下注频率规则、下注大小以及牌面结构来思考常见场景。
例如,你发现某个玩家经常在河牌面对下注弃牌。那么你就可以在河牌更频繁地诈唬来利用这个习惯。这并不是标准的 GTO 打法,但如果对手有明显漏洞,这种策略可能非常有效。
总结
博弈论最优(GTO)扑克旨在实现一种对手无法利用的策略平衡。理解 GTO 概念能够帮助你全面提升扑克水平。
虽然人类玩家很难执行完美的 GTO 策略,但像 GTO Wizard、PioSolver 和 Freebetrange 这样的工具可以帮助你建立简化的 GTO 策略。
GTO 是扑克理论的重要基础,每位玩家都应该学习这些概念。不过,完全按照 GTO 打牌并不是最赚钱的方法。扑克中最大的利润来自利用其他玩家的错误。因此,记得使用扑克 HUD,并研究MDA 方法,全面提升你的策略水平。
